ここではt検定は使えないので、別の検定方法を考えなければなりません。その方法は「分散分析」といいます。
分散分析について説明する前に、まずデータを取ってきましょう。
ワクワク、モグモグ、パクパクのポテト20個ずつを手に入れて、駅に向かい、通行人合計60人にランダムにどれかひとつのポテトを食べてもらいました。そして、そのおいしさについて、100点満点で点数をつけてもらいました。
以下が、それぞれのお店のポテトの評価データです。
| ワクワク | モグモグ | パクパク |
| 80 | 75 | 80 |
| 75 | 70 | 80 |
| 80 | 80 | 80 |
| 90 | 85 | 90 |
| 95 | 90 | 95 |
| 80 | 75 | 85 |
| 80 | 85 | 95 |
| 85 | 80 | 90 |
| 85 | 80 | 85 |
| 80 | 75 | 90 |
| 90 | 80 | 95 |
| 80 | 75 | 85 |
| 75 | 70 | 98 |
| 90 | 85 | 95 |
| 85 | 80 | 85 |
| 85 | 75 | 85 |
| 90 | 80 | 90 |
| 90 | 80 | 90 |
| 85 | 90 | 85 |
| 80 | 80 | 85 |
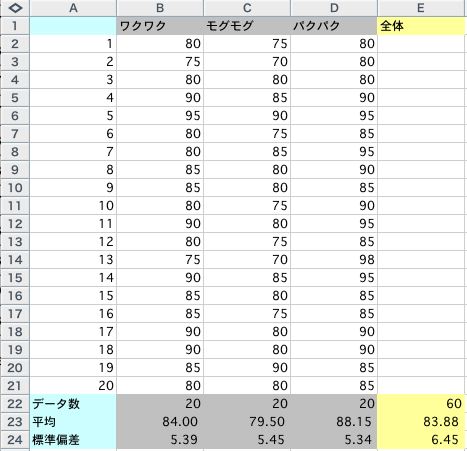
それぞれのお店のデータ数と平均と標準偏差をExcelで計算しましょう。使うのは次の関数です。
さらに、全体の、データ数と平均と標準偏差をExcelで計算しましょう。範囲をタテとヨコに広げればよいのです。
次のように計算されました。
計算結果を見ると、標準偏差はどの店もだいたい同じ。評価の平均は、パクパク(88.15)、ワクワク(84.00)、モグモグ(79.50)の順で高いようです。また、全体の平均は、83.88でした。
それでは各平均が出揃ったところで、3つ以上の平均の差の検定方法について考えてみましょう。
最初に、帰無仮説を立てることから出発します。
帰無仮説は「3つのお店のポテトの評価(母集団)の平均に差はない」です。
もっと正確に言うと「3つのお店のポテトの評価(母集団)の平均のどの組み合わせにおいても差はない」ということです。
そうすると、対立仮説は「3つのお店のポテトの評価(母集団)の平均の少なくともひとつの組み合わせに差がある」となります。
ここで、対立仮説は「すべての組み合わせに差がある」ではないことに注意してください。そうではなく「少なくともひとつの組み合わせに差がある」ということです。「すべての組み合わせに差がある」場合もこの中に含まれることになります。
それでは、分散分析の考え方について説明していきましょう。
いま、3つのお店の評価データはこんなふうになっています(分布の形はいいかげんです)。
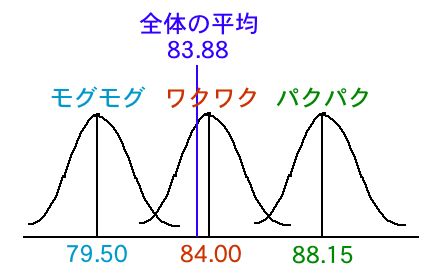
モグモグの中のひとつのデータ(●で示したもの)について考えます。
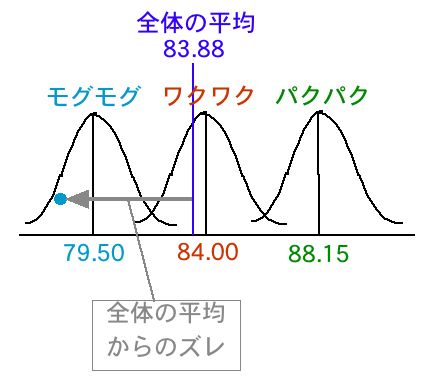
このデータは、全体の平均から矢印の分だけズレています。
よく見ると、全体の平均からのズレは、「全体の平均とモグモグの平均のズレ」と「モグモグの平均からのズレ」に分解できます。下のように。
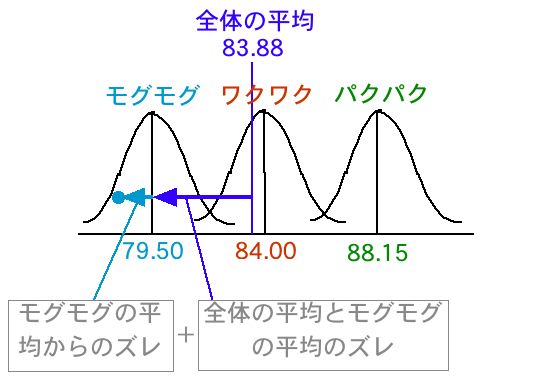
ここで、「全体の平均とモグモグの平均のズレ」は何を表しているかと考えると、これは全体の平均から各群(各標本集団)がどれほどズレているかということです。これを「群間のズレ」と呼びましょう。
一方、「モグモグの平均からのズレ」は何を表しているかというと、群(標本集団)の中で、個々のデータがどれほどズレているかということです。これを「群内のズレ」と呼びましょう。
そうすると、すべてのデータについて、全体の平均からのズレは、群間のズレと群内のズレに分解できます。
つまり、すべてのデータについて、
全体の平均からのズレ = 群間のズレ + 群内のズレ
ということが成り立ちます。
さて、群間のズレは、標本集団の間の違いを表しています。これが大きくなるということは、各群の平均が大きく異なるということです。
一方、群内のズレは、同じ標本集団の中でのばらつきですので、「誤差」や「個人差」として扱うことができます。
もし、群内のズレに比べて、群間のズレが大きければ、標本集団の間の違いが大きいということですから、「母集団の平均に差がない」という帰無仮説を棄却することになります。
逆に、群内のズレに比べて、群間のズレが小さければ、標本集団の間の違いが大きいとはいえないですから、「母集団の平均に差がない」という帰無仮説を採択することになります。
これが分散分析の考え方です。