
あなたの買ったポテトには、全部で49本はいっていました。あなたは49本のポテトの長さの平均と分散、標準偏差を計算することができます。
さて、今度はポテトの本数が気になってきました。もしかするとあなたが買ったポテトは、普通に売られているポテトより本数が少ないかもしれません。他の人が買ったポテトには60本くらいはいっていることもあるのかもしれません。
はたして、49本という数は、この店で売られているポテトの平均的本数なのでしょうか? 店員さんに聞いてみます。

「あの~、このポテトって、本数を数えているわけじゃないですよね。」
「もちろんです。そんなことは実際上できませんから。」
「確かに、そうですよね。」
「何か、気になることがありましたか?」
「いや、たいしたことじゃないんだけど、このポテトは全部で49本入っていたんですよ。それが、標準のものよりも多いのかな、それとも少ないのかな、と思ったもので。」
「お客さん、そのポテトの本数をわざわざ数えたんですか? それは、すごい。」
「そう。49本はいっていたんだけど、この数字はどうなんでしょうね。」
「うーん。どうなんだろう。自分の店で作っておきながら、そういうことは気にしたことがなかったなあ。」
「聞いたのは、そんなわけなんです。」
「うーん。本当はどうなんだろうなあ……」
たとえば、このお店で作られるすべてのポテトについて知りたいとします。このとき、「このお店で作られるすべてのポテト」のことを「母集団」と呼びます。
しかし、たいていの場合は、母集団は数が多すぎるので、全部を調べるわけにはいきません。そこで母集団の中から限られた数のデータを取ってきます。こうして取ってくることを「抽出」(あるいは「サンプリング」)と呼びます。またこうして取ってきたデータを「標本」と呼びます。
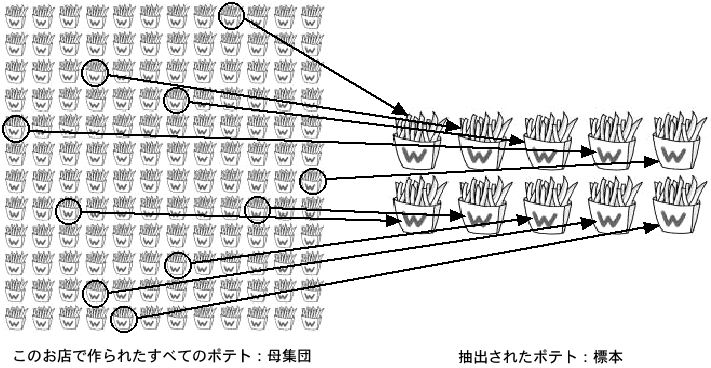
標本を抽出するときには、それを「無作為」に(あるいはランダムに)行うことが重要です。たとえば、このお店の開店時間から10個連続で標本を抽出したとすると、それはかなり偏ったものになることが予想されます。無作為に抽出するためには、たとえば1時間ごとにひとつの標本を取り出したり、50個おきにひとつの標本を取り出したりします。サイコロや乱数表などを使うこともあります。無作為に行われた抽出を「無作為抽出」(あるいは「ランダムサンプリング」)と呼びます。
標本の中のデータの数を、「標本の大きさ」あるいは「サンプルサイズ」と呼びます。
さて、あなたはワクワクバーガーでポテトを買った人を1時間ごとに一人選び、ポテトの本数を数えさせてもらいました。こうして得られたのが次のデータです。
表 ワクワクバーガーのポテトの本数(サンプルサイズ=10)
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
47 |
51 |
49 |
50 |
49 |
46 |
51 |
48 |
52 |
49 |
このデータから、平均、分散、標準偏差を計算してみましょう。
◇
実際にExcelを使って計算しましょう
◇