母集団から標本を取り出して計算した標本平均は、母平均の推定値として使うことができます。しかし、それは母平均にぴったり一致しているわけではありません。あくまでも推定値です。サンプルサイズが小さければ、標本平均と母平均が離れている可能性が高くなりそうですし、逆に、サンプルサイズが大きければ、標本平均と母平均とが近くなるような気がします。
そこで、母平均を、ある幅を持って推定しようということを考えます。これを「区間推定」と呼びます。「標本から推定すると、母平均はこの値からこの値までの間にはいるのではないか」という形で推定をおこなうのです。
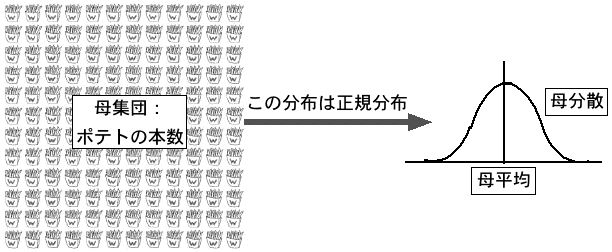
区間推定の考え方を説明していきましょう。 まずポテトの母集団の分布を考えます。この分布が「正規分布」にしたがっているとします。正規分布というのは、下の図のように平均を山の中心として左右になめらかに広がった「つりがね型」をした分布です。
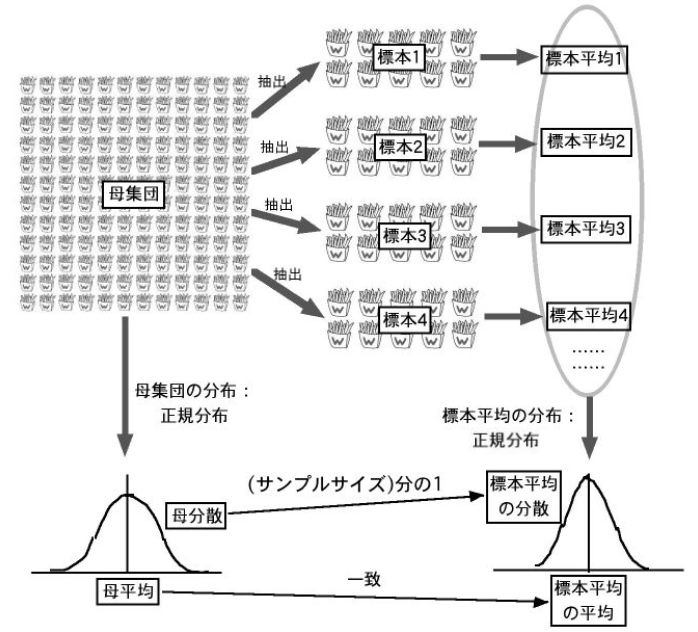
次に、サンプルサイズを10として、母集団から10個のデータを取ります。この平均を計算して、それを標本平均1とします。標本を戻して、もう一度10個のデータを取ります。その平均を標本平均2とします。このようなことを何回も繰り返します。
このとき標本平均の分布を描いてみると、これもまた正規分布に従います。そのときの平均値は母平均に一致します。また分散は母分散の10分の1、つまり「(サンプルサイズ)分の1」になります。
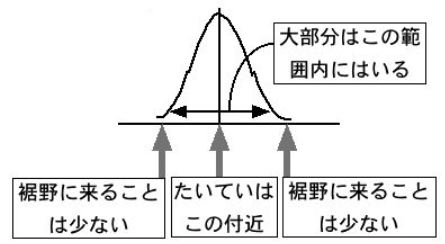
いま、標本平均をひとつ取ったとすると、その値は下の標本平均の分布図の矢印の範囲内に大体はいります。もちろん平均に近い値になることが多く、それから外れた裾野の方の値になることはめったにありません。
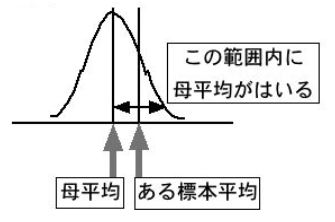
ここまで、標本を何回も取ることを考えてきましたが、通常私たちが標本を取るのは一回限りのことです。そこで、一回限りの標本を取ったときに、その平均値が推定したい母平均を含んでいるような範囲はどうなるかということを考えます。たとえば、標本平均が下の図のように母平均から少しずれていたとしたら矢印の範囲を指定すれば、母平均を含んでいることになります。
次の問題は、母平均を含むような範囲を決めるときに、どのような範囲にすればいいかということです。統計学では、伝統的に「95%の確率で母平均が含まれるような範囲」を使います。もっと厳しくしたいときには「99%の確率で母平均が含まれるような範囲」を使います。これをそれぞれ「95%信頼区間」、「99%信頼区間」と呼びます。
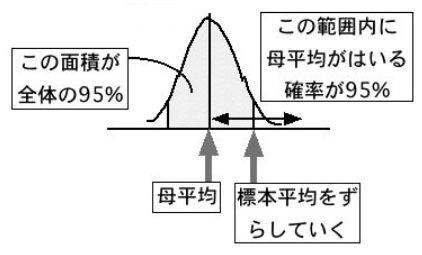
母平均から標本平均を左右にずらしていきます。左右の標本平均で囲まれた部分の面積が全体の95%になるまでずらしていきます。そのとき、その標本平均から母平均までの差を取り、それを標本平均の範囲とすれば、その範囲に母平均が含まれる確率がちょうど95%になります。この原理で、95%信頼区間を求めます。
信頼区間を計算していきましょう。 まず、母平均の推定値として、標本平均を使います。 次に、標本平均の分布の分散の推定値として、母分散を標本数で割ったものを使います。ここで、母分散は不偏分散で推定します。つまり、次のようになります。
標本平均の分散=(母分散/サンプルサイズ)=(不偏分散/標本数)
標本平均の標準偏差=(不偏分散/サンプルサイズ)の平方根
標本平均の標準偏差を「標本標準誤差」(SE=standard error)と呼びます。
さて、これで信頼区間を求めることができます。
信頼区間=標本平均±t×標本標準誤差
このとき「t」は信頼区間で決められた分布の面積が95%になるような数値です。この「t」の具体的な値を決めるために、t分布を変形して、平均が0、標準偏差が1のt分布を作ります。t分布は正規分布に似ていますが、サンプルサイズによって形が少し変わります(後述します)。
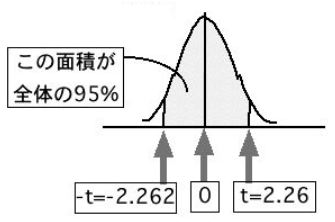
サンプルサイズ10のときのt分布を作ってみると、-tからtまでで挟まれた面積が全体の95%になるようなtの値は2.262になります。また、99%の場合は3.250になります。
これで信頼区間の計算ができます。標本平均は49.2でしたので
信頼区間=49.2±2.262×標本標準誤差
不偏分散は3.51でしたので、
標本標準誤差=sqrt(3.51/10) ★sqrtは平方根を求める関数です★
=0.592
よって
信頼区間=49.2±2.262×0.592
=49.2±1.34
=47.86~50.54
つまり、47.86から50.54が95%信頼区間になります。この意味は、母平均が95%の確率で47.86から50.54までの間に含まれるということです。
◇
それでは今度は99%信頼区間を計算してみましょう。99%のときのtの値は3.250になりますので、
信頼区間=49.2±3.250×標本標準誤差
不偏分散は3.51でしたので、
標本標準誤差=sqrt(3.51/10)=0.592
よって
信頼区間=49.2±3.250×0.592
=49.2±1.924
=51.124~47.276
さて、信頼区間を計算したあなたは再び店員さんに報告しに行きました。

「10個の標本データからこのお店全体のポテトの本数の平均を推定すると、49.2本になりました。もちろんこれは推定値なので、ぴったりこの値になるとは限りません。そこで95%の確率で母平均を含んでいるような範囲を計算します。それは、47.86本から50.54本の間だということがわかりました。」
「へえええ。こりゃまたすごいねえ。母平均の範囲までわかるんだ。でも、「95%の確率で」っていうのは一体誰が決めたんだい?」
「ん~。95%の確率で母平均がこの範囲にあるということは、5%の確率で、この範囲の外にある場合もあるということです。しかし、それは5%の確率でしか起こらないわけですからめったには起こりません。そこで、95%の確率でよしとしようということです。」
「いいかえれば、20回に1回はハズレになるわけですが、それでよしとするということです。もちろんもっと厳しくしたいという要望があれば、99%を基準に取ることもできます。その場合は100回に1回しかハズレになりません。ですからより堅実に母平均のはいりそうな範囲を推定することができます。」
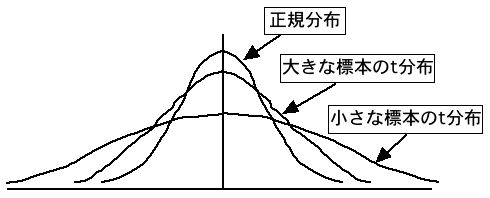
t分布は正規分布に似たつりがね型の分布ですが、サンプルサイズによって少しずつ形が違っています。標本数が小さいときは、正規分布よりも平べったい形になります。逆にサンプルサイズが大きいときは正規分布に近づいていきます。サンプルサイズが無限大のとき、正規分布に一致します。
信頼区間を計算するためには、サンプルサイズに応じてt分布の95%と99%の値を知る必要があります。そこで下のようなt分布表がよく使われます。
t分布表
|
自由度 |
確率95% |
確率99% |
1 |
12.706 |
63.657 |
2 |
4.303 |
9.925 |
3 |
3.182 |
5.841 |
4 |
2.776 |
4.604 |
5 |
2.571 |
4.032 |
6 |
2.447 |
3.707 |
7 |
2.365 |
3.499 |
8 |
2.306 |
3.355 |
9 |
2.262 |
3.250 |
10 |
2.226 |
3.169 |
|
11 |
2.201 |
3.106 |
|
12 |
2.179 |
3.055 |
|
13 |
2.160 |
3.021 |
|
14 |
2.145 |
2.977 |
|
15 |
2.131 |
2.947 |
|
16 |
2.120 |
2.921 |
|
17 |
2.110 |
2.898 |
|
18 |
2.101 |
2.878 |
|
19 |
2.093 |
2.861 |
|
20 |
2.086 |
2.845 |
21 |
2.080 |
2.831 |
22 |
2.074 |
2.819 |
23 |
2.069 |
2.807 |
24 |
2.064 |
2.797 |
25 |
2.060 |
2.787 |
26 |
2.056 |
2.779 |
27 |
2.052 |
2.771 |
28 |
2.048 |
2.763 |
29 |
2.045 |
2.756 |
|
30 |
2.042 |
2.750 |
|
40 |
2.021 |
2.704 |
|
60 |
2.000 |
2.660 |
|
120 |
1.980 |
2.617 |
|
∞ |
1.960 |
2.576 |
この表で「自由度」というのはサンプルサイズから1を引いたものです。たとえばサンプルサイズが10のとき、自由度は9になります。
なお、この表に自由度が見あたらないときは、近い自由度の値を使ってください。たとえば、自由度32であれば、近い自由度である30を使います。実用上はそれで問題はありません。
また、300や500というような大きな自由度の時は「∞(無限大)」の値を使ってください。
◆
それでは、ここまでの内容をまとめてみましょう。
それについて知りたいと思う、全体のデータを母集団という
母集団からいくつか取り出したデータを標本という
そのデータの数をサンプルサイズという
よい標本を取り出すためには、無作為(ランダム)に抽出することが必要
母平均は標本の平均で推定できる
母分散は標本の不偏分散で推定できる
不偏分散=((データ-平均値)の二乗)の総和/(個数-1)
母平均が95%の確率で含まれているような範囲を95%信頼区間という
信頼区間=標本平均±t×標本標準誤差
標本標準誤差=(不偏分散/サンプルサイズ)の平方根
tの値は、確率(95%や99%)と自由度によって変わるので、t分布表を見る
サンプルサイズから1引いたものを自由度という