

偝偰丄儚僋儚僋僶乕僈乕偲儌僌儌僌僶乕僈乕偺枴偺昡壙偺娫偵堄枴偺偁傞嵎乮桳堄嵎乯偑偁傞偐偳偆偐傪寛傔傞曽朄傪峫偊偰偄偒傑偟傚偆丅
偦偺偨傔偵偼丄慜偺復偱愢柧偟偨壖愢専掕偺峫偊曽傪巊偄傑偡丅
壖愢専掕偺峫偊曽偼師偺傛偆側傕偺偱偡丅
崱丄俀偮偺曣廤抍A,B傪峫偊傑偡丅A傕B傕丄偩偄偨偄惓婯暘晍偵偟偨偑偭偰偍傝丄暯嬒抣偑摍偟偔丄暘嶶傕傎傏摍偟偄偲偟傑偡丅
偦偺俀偮偺曣廤抍A,B偦傟偧傟偐傜NA, NB屄偺昗杮傪庢傝弌偟偰偒傑偡丅偦傟傪昗杮廤抍A,B偲偟傑偡丅
昗杮廤抍A,B偺偦傟偧傟偺暯嬒抣傪寁嶼偟偰丄偦傟傪昗杮暯嬒A,B偲偟傑偡丅
昗杮暯嬒A偲昗杮暯嬒B偺嵎傪寁嶼偟傑偡丅偡傞偲丄偙傟偼0偵嬤偄応崌偑懡偄偲峫偊傜傟傑偡丅側偤側傜丄傕偲傕偲偺曣廤抍A,B偺暯嬒抣偑摍偟偄偐傜偱偡丅偦偙偐傜庢傝弌偟偨昗杮廤抍A,B偺暯嬒抣傕偍屳偄偵嬤偄応崌偑懡偄偺偱偼側偄偐偲悇應偱偒傑偡丅
偦偙偱丄師偺傛偆側巜昗t傪峫偊傑偡丅
t亖乮昗杮暯嬒偺嵎乯乛乮昗杮暯嬒偺嵎偺昗弨岆嵎乯
偡傞偲丄偙偺t偼丄帺桼搙乮NA+NB-2乯偺t暘晍偵廬偆偙偲偑抦傜傟偰偄傑偡丅
昗杮暯嬒偺嵎偺昗弨岆嵎偼丄慜偺愡偱傗偭偨傛偆偵丄師偺幃偱悇掕偟傑偡丅
昗杮暯嬒偺嵎偺昗弨岆嵎亖sqrt乮乮A偺晄曃暘嶶乛A偺昗杮悢乯亄乮B偺晄曃暘嶶乛B偺昗杮悢乯乯
偙偙偱丄A偲B偺曣暘嶶偼摍偟偄偲偟偰丄乽悇掕曣暘嶶乿偲昞婰偡傞偲丄
嵎偺昗杮昗弨岆嵎亖sqrt乮乮悇掕曣暘嶶乛昗杮悢A乯亄乮悇掕曣暘嶶乛昗杮悢B乯乯
丂丂丂丂丂丂丂丂亖sqrt乮悇掕曣暘嶶亊乮乮1乛昗杮悢A乯亄乮1乛昗杮悢B乯乯
悇掕曣暘嶶偼師偺幃偱悇掕偟傑偡丅偙傟偼晄曃暘嶶傪媮傔傞曽朄偲摨偠偱丄暯嬒偐傜偺曃嵎偺暯曽榓乮偙傟偼暘嶶傪媮傔傞偲偒偺乮乮僨乕僞亅暯嬒抣乯偺俀忔乯偺憤榓偺偙偲偱偡乯傪乮昗杮悢亅1乯偱妱偭偨傕偺偵憡摉偟傑偡丅
悇掕曣暘嶶亖乮昗杮A偺暯嬒偐傜偺曃嵎偺暯曽榓亄昗杮B偺暯嬒偐傜偺曃嵎偺暯曽榓乯乛乮乮昗杮悢A亅1乯亄乮昗杮悢B亅1乯乯
傑偲傔傞偲丄
t亖乮昗杮暯嬒偺嵎乯乛sqrt乮悇掕曣暘嶶亊乮乮1乛昗杮悢A乯亄乮1乛昗杮悢B乯乯
悇掕曣暘嶶亖乮昗杮A偺暯嬒偐傜偺曃嵎偺暯曽榓亄昗杮B偺暯嬒偐傜偺曃嵎偺暯曽榓乯乛乮乮昗杮悢A亅1乯亄乮昗杮悢B亅1乯乯
偲側傝傑偡丅
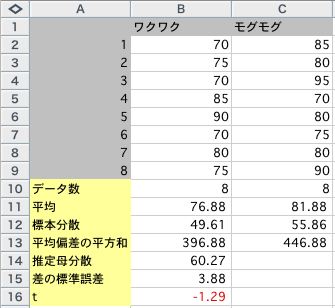
偦傟偱偼丄幚嵺偵儚僋儚僋僶乕僈乕偺昡壙揰偲儌僌儌僌僶乕僈乕偺昡壙揰偵偮偄偰丄t傪寁嶼偟偰傒傑偟傚偆丅
傑偢丄昗杮暯嬒偺嵎偼丄
昗杮暯嬒偺嵎亖76.88-81.88
丂丂丂丂丂丂亖-5.00
師偵丄嵎偺昗弨岆嵎傪媮傔傑偡丅
儚僋儚僋僶乕僈乕偺昡壙揰偺昗杮暘嶶亖49.61
丂偦偺暯嬒偐傜偺曃嵎偺暯曽榓亖49.61亊8
儌僌儌僌僶乕僈乕偺昡壙揰偺昗杮暘嶶亖55.86
丂偦偺暯嬒偐傜偺曃嵎偺暯曽榓亖55.86亊8
悇掕曣暘嶶亖乮49.61亊8亄55.86亊8乯乛乮乮8-1乯亄乮8-1乯乯
丂丂丂丂丂亖60.27
嵎偺昗杮昗弨岆嵎亖sqrt乮60.27亊乮乮1/8乯亄乮1/8乯乯乯
丂丂丂丂丂丂丂丂亖3.88
偦偆偡傞偲丄t偼偙偆側傝傑偡丅
t亖-5.00乛3.88
丂亖-1.29
Excel偱寁嶼偟偰傒傑偟傚偆丅
偙偙偱偼丄師偺傛偆側娭悢傪巊偭偰偄傑偡丅
Excel偺娭悢偵偮偄偰偼丄偦偺堄枴偑棟夝偱偒偰偄傟偽丄愊嬌揑偵巊偭偰偐傑偄傑偣傫丅
偝偰丄t=-1.29偲側傝傑偟偨丅偙偺抣偼偳偺偔傜偄偺妋棪偱婲偙傞偺偱偟傚偆偐丅
偦傟傪挷傋傞偨傔偵偼丄t暘晍昞傪巊偄傑偡丅
t暘晍偼帺桼搙偵傛偭偰彮偟偢偮曄傢偭偰偒傑偡丅t専掕偺応崌偼丄乮昗杮悢A-1乯偲乮昗杮悢B-1乯傪懌偟偨傕偺偑帺桼搙偵側傝傑偡丅偙偺応崌丄昗杮悢A傕丄昗杮悢B傕8偱偟偨偺偱丄(8-1)+(8-1)偱丄帺桼搙偼14偵側傝傑偡丅
偦傟偱偼丄t暘晍昞偺帺桼搙14偺偲偙傠傪尒偰偔偩偝偄丅
t暘晍昞
| 帺桼搙 |
桳堄悈弨5% |
桳堄悈弨1% |
1 |
12.706 |
63.657 |
2 |
4.303 |
9.925 |
3 |
3.182 |
5.841 |
4 |
2.776 |
4.604 |
5 |
2.571 |
4.032 |
6 |
2.447 |
3.707 |
7 |
2.365 |
3.499 |
8 |
2.306 |
3.355 |
9 |
2.262 |
3.250 |
10 |
2.226 |
3.169 |
| 11 |
2.201 |
3.106 |
| 12 |
2.179 |
3.055 |
| 13 |
2.160 |
3.021 |
| 14 |
2.145 |
2.977 |
| 15 |
2.131 |
2.947 |
| 16 |
2.120 |
2.921 |
| 17 |
2.110 |
2.898 |
| 18 |
2.101 |
2.878 |
| 19 |
2.093 |
2.861 |
| 20 |
2.086 |
2.845 |
21 |
2.080 |
2.831 |
22 |
2.074 |
2.819 |
23 |
2.069 |
2.807 |
24 |
2.064 |
2.797 |
25 |
2.060 |
2.787 |
26 |
2.056 |
2.779 |
27 |
2.052 |
2.771 |
28 |
2.048 |
2.763 |
29 |
2.045 |
2.756 |
| 30 |
2.042 |
2.750 |
| 40 |
2.021 |
2.704 |
| 60 |
2.000 |
2.660 |
| 120 |
1.980 |
2.617 |
| 亣 |
1.960 |
2.576 |
帺桼搙14偵偍偄偰丄桳堄悈弨5%偺t偼2.145丄桳堄悈弨1%偺t偼2.977偲彂偄偰偁傝傑偡丅
偙傟偼師偺偙偲傪堄枴偟偰偄傑偡丅
帺桼搙14偺偲偒偺t暘晍傪昤偄偰傒傞偲丄t偑2.977傛傝傕戝偒偄丄傑偨偼-2.977傛傝傕彫偝偄偙偲偑婲偙傞妋棪偑1%枹枮偱偁傞偲偄偆偙偲傪帵偟偰偄傑偡丅
傑偨丄t偑2.145傛傝傕戝偒偄丄傑偨偼-2.145傛傝傕彫偝偄偙偲偑婲偙傞妋棪偑5%枹枮偱偁傞偲偄偆偙偲傪帵偟偰偄傑偡丅
t偑2.977傛傝傕戝偒偄丄傑偨偼-2.977傛傝傕彫偝偄晹暘傪丄1%桳堄悈弨偱偺婞媝堟偲屇傃傑偡丅
摨條偵丄t偑2.145傛傝傕戝偒偄丄傑偨偼-2.145傛傝傕彫偝偄晹暘傪丄5%桳堄悈弨偱偺婞媝堟偲屇傃傑偡丅
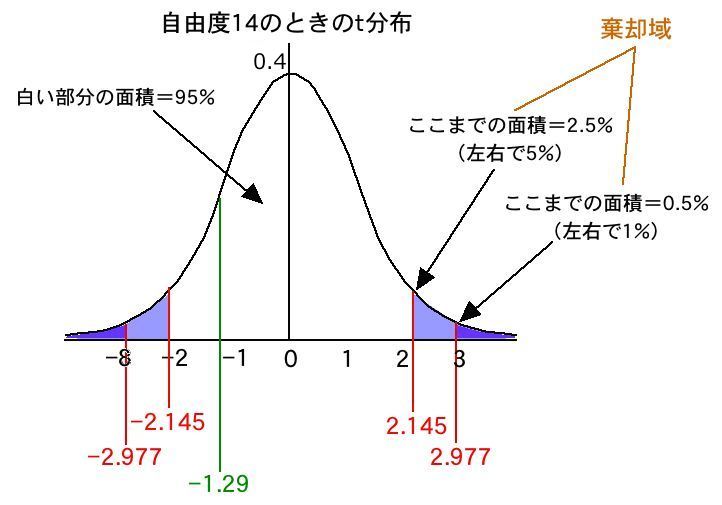
偄傑丄桳堄悈弨傪5%偵愝掕偟偨偲偡傞偲丄t偑2.145傛傝傕戝偒偄偐丄-2.145傛傝傕彫偝偗傟偽乮婞媝堟偵擖偭偰偄傞乯丄偦傟偑婲偙傞妋棪偼5%枹枮側偺偱丄俀偮偺曣廤抍偺暯嬒丄偮傑傝儚僋儚僋偲儌僌儌僌偺昡壙揰偺暯嬒偵偼嵎偑側偄偲偟偨婣柍壖愢偑婞媝偝傟傑偡丅寢榑偲偟偰偼丄儚僋儚僋偲儌僌儌僌偺昡壙揰偺暯嬒偵偼嵎偑側偄偲偼偄偊側偄丄偮傑傝丄嵎偑偁傞偲偄偆偙偲偵側傝傑偡丅
偝偰丄寁嶼偟偨t偼丄-1.29偱偟偨偺偱丄5%桳堄悈弨偱偺婞媝堟偵偼擖偭偰偄傑偣傫丅偟偨偑偭偰婣柍壖愢偼婞媝偱偒傑偣傫丅寢榑偲偟偰偼丄儚僋儚僋偲儌僌儌僌偺昡壙揰偺暯嬒偵偼嵎偑側偄偲偄偆偙偲偵側傝傑偡丅
偙傟偱t専掕偑姰惉偟傑偟偨丅
傕偆堦搙丄t専掕偺庤懕偒傪傑偲傔偰傒傑偟傚偆丅
1.丂婣柍壖愢傪棫偰傞丗
乽儚僋儚僋僶乕僈乕乮慡懱乯偲儌僌儌僌僶乕僈乕乮慡懱乯偺偍偄偟偝偺昡壙揰偵偼嵎偑側偄乿
2.丂婣柍壖愢偺斲掕偱偁傞懳棫壖愢傪棫偰傞丗
乽儚僋儚僋僶乕僈乕乮慡懱乯偲儌僌儌僌僶乕僈乕乮慡懱乯偺偍偄偟偝偺昡壙揰偵偼嵎偑側偄偲偼偄偊側偄丄偮傑傝丄嵎偑偁傞乿
3.丂桳堄悈弨傪寛傔傞
捠忢偼丄尩偟偔偰1%丄彮偟娒偔偰5%
4.丂摼傜傟偨昗杮傪巊偭偰丄巜昗t傪寁嶼偡傞丗
t亖乮昗杮暯嬒偺嵎乯乛sqrt乮乮A偺晄曃暘嶶乛A偺昗杮悢乯亄乮B偺晄曃暘嶶乛B偺昗杮悢乯乯
5.丂昗杮偺悢偐傜帺桼搙傪寁嶼偡傞丗
帺桼搙亖乮A偺昗杮悢亅1乯亄乮B偺昗杮悢亅1乯亖A偺昗杮悢亄B偺昗杮悢亅2
6.丂t暘晍昞偺奩摉偡傞帺桼搙偺偲偙傠傪尒偰丄媮傔偨t偑婞媝堟偵偼偄偭偰偄傞偐丄偄側偄偐傪敾掕偟丄婣柍壖愢傪婞媝偡傞偐丄嵦戰偡傞偐傪寛傔傞
傕偟t偑婞媝堟偵擖偭偰偄側偗傟偽丄婣柍壖愢傪嵦戰偡傞
傕偟t偑婞媝堟偵擖偭偰偄傟偽丄婣柍壖愢傪婞媝偟丄懳棫壖愢傪嵦戰偡傞
7.丂寢榑傪寛傔傞
婣柍壖愢傪嵦戰偟偨応崌偼丄乽儚僋儚僋僶乕僈乕乮慡懱乯偲儌僌儌僌僶乕僈乕乮慡懱乯偺偍偄偟偝偺昡壙揰偵偼嵎偑側偄乿
懳棫壖愢傪嵦戰偟偨応崌偼丄乽儚僋儚僋僶乕僈乕乮慡懱乯偲儌僌儌僌僶乕僈乕乮慡懱乯偺偍偄偟偝偺昡壙揰偵偼嵎偑側偄偲偼偄偊側偄丄偮傑傝丄嵎偑偁傞乿
埲忋偑t専掕偺庤懕偒偱偡丅