
「じゃーん。これが『アイスクリームの好みについてのアンケート』です!」


───わあー、店長すごいじゃないですか。
「いや、実は、三ヶ島くんに手伝ってもらったんだけどね……」
───でも、性別や年齢はいいとしても、出生順を聞いているのはなんでですか?
「いや、ちょっとした仮説があってね」
───店長が「仮説」なんてことばを使うなんて! いったいどんな仮説なんですか?
「いや、その。一人っ子はミルク系が好きかな〜、長子は渋め系が好きかな〜、って感じなんだけど」
───……なんか、かなりいい加減な仮説ですね。
「まあ、いいじゃないか。とにかくこのアンケートを実施して、もうデータは取ってあるんだよ」
───わあ、行動が速いですね。
「えへ。これがデータだよ。20歳前後の男女40人ずつにやってもらった。でね……」
───ま、まさか。
「アイ子ちゃん、お願い。これを分析してくれないか」
このようなアンケートでは、変数がたくさんあります。性別、年齢、出生順、アイスクリームを食べる頻度、そして、バニラの好き嫌い、ストロベリーの好き嫌い、ミルクティーの好き嫌い、……、あずきの好き嫌い。これらのすべてが変数になるわけです。
このようなデータを「多変量データ」と呼びます。たくさんの変数からなっているデータという意味です。「変量」と「変数」とは同じ意味です(英語では variables )。
多変量データを入力するときは、次のような形式を取ります。
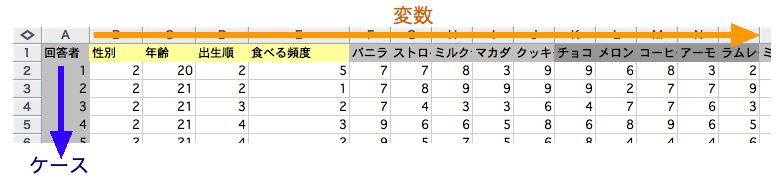
横方向(列)には変数を並べます。ここでは、性別、年齢や、各種アイスクリームの好みの度合いが並びます。
縦方向(行)にはケース(個別にワンセットになったデータ)を並べます。ここでは、回答者が並びます。
(注意) ここでは、性別の男性に1、女性に2という数字を割り当てています。また、出生順では、一人っ子は1、長子は2、中間子は3、末っ子は4という数字を割り当てています。こうした割り当ては、適宜自分で決めることができます。
(C) 2003 KogoLab